How effective is my research programming workflow? The Philip Test – Part 1
Philip Guo, who writes a wonderful blog on his views and experiences of academia – including a lot of interesting programming stuff – came up with a research programming version of The Joel Test last summer, and since then I’ve been thinking of writing a series commenting on how well I fulfil each of the items on the test.
For those of you who haven’t come across The Joel Test – it’s a list of simple Yes/No questions you can answer to measure the quality of your software team. Questions include things like: Do you use source control? and Can you make a build in one step? Philip came up with a similar set of questions for research programmers (that is, people who program as part of their research work – which includes researchers in a very wide range of fields these days).
So, starting with the first few questions:
1. Do you have reliable ways of taking, organizing, and reflecting on notes as you’re working?
2. Do you have reliable to-do lists for your projects?
These are probably the most important questions on the list, but it’s something that I’ve often struggled to do well. I often wish for a system like the prototype that Philip developed as part of his PhD (see here), but that wasn’t suitable for use in production. Instead, I tend to make do with a few different systems for different parts of my work.
I have a large ‘logbook’ for my main PhD work (it’s even got the logo of my University on it, and some pages at the back with information on Intellectual Property law), which I try and use as much as possible. This includes comments on how things are working, notes from meetings with my supervisors, To Do lists and so on. When I want to keep electronic notes on my PhD I tend to keep long notes in LaTeX documents (I can write LaTeX documents almost effortlessly now) like my PhD status document (a frequently-updated LaTeX document that I have which has the planned structure of my PhD thesis in it, with the status of each piece of work, and planned completion dates). I often keep shorter notes in Simplenote – a lovely simple web-based ASCII text note system, which synchronises with Notational Velocity for OS X and Resoph Notes for Windows.
For my other academic-related work, I tend to make notes in simple text files (I’m a big fan of README.txt files in project folders), Simplenote, or Trello. For managing my academic software (such as Py6S and RTWTools) I tend to use Trello, with a board for each project, and cards for To Do items, bugs and so on.
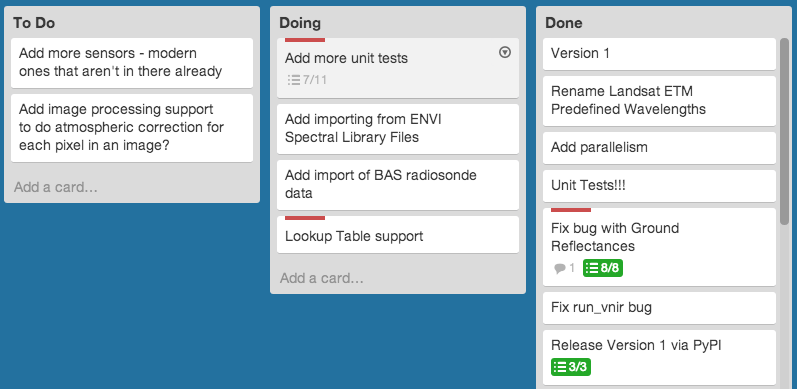
I also keep my Research Ideas list in Trello – and try and keep it updated as often as possible.
3. Do you write scripts to automate repetitive tasks?
Yes – to an extreme extent, because I’ve been burnt too many times.
I now get scared when I have to do proper analysis through a non-scriptable method – because I know that I’ll have to repeat it at some point, and I know it’ll take a lot of work. I’ve just finished the analysis for a project which is entirely reproducible, apart from a key stage in the middle where I have to export the data as a CSV file and manually classify each row into various categories. That scares me, because when it all needs redoing for whatever reason, the rest of the analysis can be run with a click of a button, but this bit will require a lot of work.
In that example – as in most cases – the manual work probably could be automated, but it’d take so much effort that it (probably) wouldn’t be worth it. It still scares me though…
Looking at this more positively, I find that I’m quite unusual in exactly how much I automate. I know quite a few people who will automate some particularly frustrating repetitive tasks, such as renaming files or downloading data from a FTP site, but I try and do as much of my analysis as possible in code. This really shines through when I need to do the analysis again: I can click a button and go and have a break while the code runs, whereas my colleagues have to sit there clicking around in the GUI to produce their results.
In terms of the tools that I use to do this, they vary depending on what I’m trying to do:
- For specific tasks in certain pieces of software, I’ll often use the software’s own scripting interface. For example, if there is already an ENVI function that does exactly what I want to do – and if it is something relatively complex that it would take a lot of effort to implement myself – I’ll write some IDL code to automate running the process in ENVI. Similarly, I’d do the same for ArcGIS, and even Microsoft Office.
- For filesystem-related tasks, such as organising folder hierarchies, moving, copying and renaming files, I tend to either use unix commands (it’s amazing what can be done with a few commands like
find,mvandgrepcombined together), simple bash scripts (though I am by no means an expert) or write my own Python code if it is a bit more complex. - For most other things I write Python code – and I tend to find this the most flexible way due to the ‘batteries included’ approach of the standard library (and the Python Module of the Week website to find out how best to use it) and the wide range of other libraries that I can interface with. I’ll be posting soon on my most frequently-used Python modules – so look out for that post.
So, that’s the first three items on the Philip Test – stay tuned for the next three.
If you found this post useful, please consider buying me a coffee.
This post originally appeared on Robin's Blog.
Categorised as: Academic, Programming
Do you write scripts to automate repetitive tasks?
See http://xkcd.com/1319/
[…] article was first published on Robin's Blog » R, and kindly contributed to […]
[…] items on the Philip Test. The first part, with an explanation of exactly what this is, is available here, this time we’re moving on to the next three items in the […]