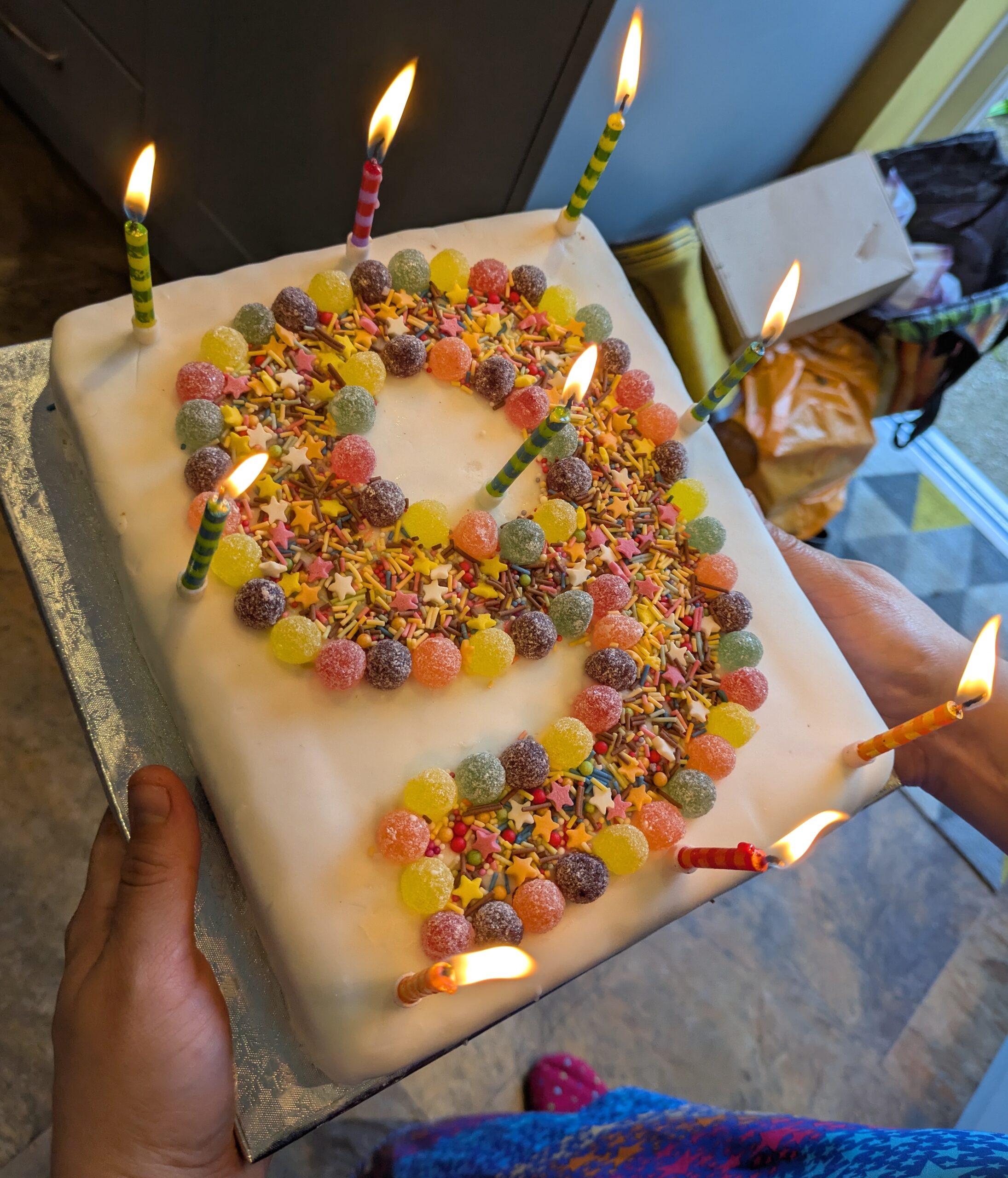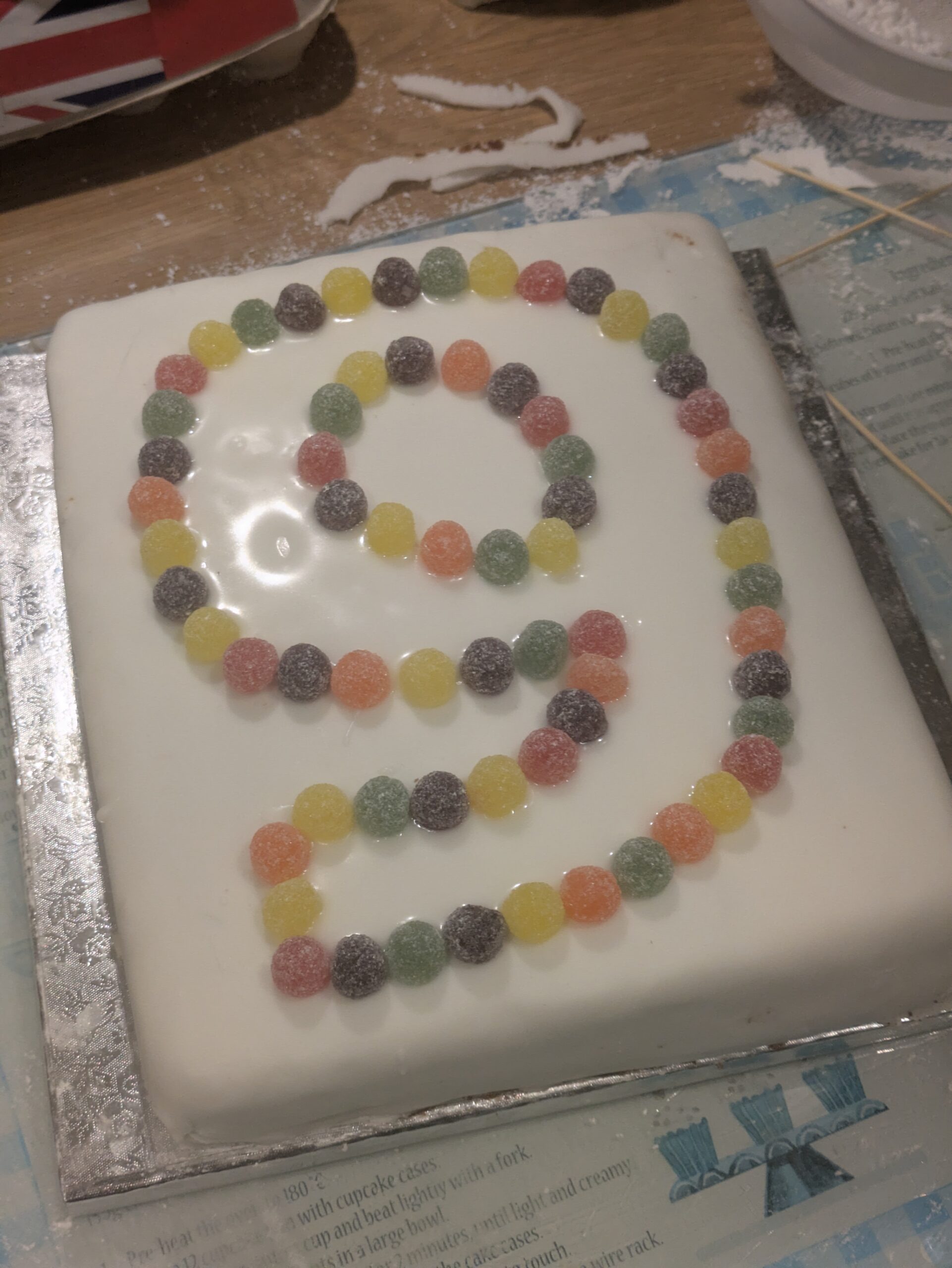I quite like making decorated birthday cakes (I’ll show some of my favourites at the end of this post), but they generally take quite a lot of time and effort to make. My son doesn’t really like cake – he prefers biscuits – so I tend to make some decorated biscuits for his actual birthday, and then a simply decorated birthday cake for his party.
I’ve done the same style of decoration for nearly all of his parties, and I repeated it again for his 9th birthday this year. I’ve had quite a few compliments about it, so thought I’d write a tutorial on how to create it.
The result of these instructions will be a cake like the picture above – a cake flat-iced with roll-out icing with a number outlined on the top. It is fairly simple to make, but it’s useful to know a few tricks to make it easier. You can click on any of the pictures below to make them bigger. So, let’s get started:
Step 1:
Bake a cake (it’s like ‘First catch your rabbit’ isn’t it?). I won’t give you instructions on how to bake a cake, as it’ll depend on what sort of cake you want (I had to make mine gluten free). Bake it in a low, large-ish pan – you’re aiming for a cake that is roughly the size of an A4 (or Letter) piece of paper, maybe a little smaller. Once baked, trim the cake to make the edges flat and square.
Step 2:
Cover the cake in something to help the roll-out icing stick. I used Golden Syrup that I’d put in the microwave for 30s to make it a more easily spreadable consistency, but you could also use jam (seedless/smooth varieties work best).
Step 3:
Roll out the icing until it’s large enough to cover the top and sides of the cake. Pick it up carefully and place it over the cake. Smooth it down to get it nice and flat – you can do this by hand or use a cake smoothing tool like shown in the photo.
Step 4:
Cut the excess off the edges, smooth the edges too and tidy up any little mistakes you made (I had to do quite a bit of this, as I rolled it out a bit too thinly). If you need to add more icing to cover up a hole then roll out a bit, push it over the hole and then keep stroking it gently with your finger to make it blend into its surroundings. You should end up with a nice, flat, simply iced cake. Of course, I’ve used white icing here, but you could use any colour – either buy coloured icing, or knead in some colouring paste before rolling it out.
Step 5:
Measure the size of the top of the cake and use a computer to create a number that will fit on the cake. You could do this in all sorts of software – Word or Powerpoint will work, so will Inkscape, or anything similar. I find that the Arial Black font works for fairly bold numbers, but feel free to experiment. If you’re using a vector editing tool like Inkscape you can convert the text to a vector object and then edit the individual vertices if you want to change the design at all. Of course you can do this with any bold object you can print out – it doesn’t have to be a number. Print it out.
Step 6:
Line up the number on the top of the cake and poke some cocktail sticks through the paper and into the icing and cake to hold it in the right place. Make sure these cocktail sticks are somewhere around the border of the shape.
Step 7:
Use another cocktail stick to poke through the paper and into the icing, making little holes following the edge of the shape.
Step 8:
Remove the cocktail sticks and take the paper off. You should find you have a nice pricked outline for the edge of the shape.
Step 9:
Make up some simple glace icing by mixing some icing sugar (powdered sugar) with water until you get a reasonable consitency. You don’t want it to be too runny – it should be easy to spread but should stay where it is put. Find some sweets to use as the border – I used Jelly Tots, but all sorts of things would work.
Step 10:
Using a palette knife or a small spoon, spread the glace icing inside the pricked outline, covering the pricked holes but not going too far outside them
Step 11:
Stick sweets to the cake following the outline. To make it look nice, try not to have two sweets of the same colour next to each other.
Step 12:
Fill the middle of the shape with sprinkles or other sorts of sweets – I usually use a mix of different types of multi-coloured or chocolate sprinkles, but have used marshmallows and chocolate chips sometimes.
Step 13:
Use your fingers or a small brush to get rid of the sprinkles that are outside of the shape. You’re done! It should look something like this:
Some examples of other ones I’ve made:
Other decorated cakes I’ve made:
Now I’ve shown you how to do a simple cake, I can show off a bit with some of the more complicated cakes. Again, click on the image to enlarge. First, a fire engine for my son:
A friend was using GDAL’s ogr2ogr command to import some data to PostGIS recently, and as part of the import they were doing a reprojection of the data.
They got the following error:
PROJ: Cannot open https://cdn.proj.org/uk_os_OSTN15_NTv2_OSGBtoETRS.tif: schannel: the certificate or certificate
chain is based on an untrusted root
They’ve had various SSL errors on their computer due to their company’s IT provider providing self-signed root certificates, or screwing up SSL settings in some other way.
She’s waiting for the IT provider to try and sort things out, but as a temporary measure, we managed to find a way to disable SSL verification for PROJ. This obviously reduces security, but I don’t think it’s a major issue as PROJ is just downloading publicly available conversion data to do accurate conversions between different co-ordinate systems. It’s also temporary, until the IT provider sort things out.
Anyway, to bypass SSL verification for PROJ, set the PROJ_UNSAFE_SSL environment variable to 1. For example, with:
export PROJ_UNSAFE_SSL=1
on Linux, or:
set PROJ_UNSAFE_SSL=1
Anyway, there doesn’t seem to be much documentation on this online – I eventually found this Github issue discussion and once I knew the environment variable name, I found it in the PROJ source code. I thought documenting it here may help other people find it.
Some data analysis I’ve done has been featured in the Financial Times today – see this article (the link may not work any more unless you have a FT subscription – sorry).
The brief story is that I had terrible back pain over Christmas, and spoke to an out-of-hours GP on the phone who prescribed me some muscle relaxant and some strong painkillers. This was at 9pm on a Sunday, so I asked her where my wife could go to pick up the prescription and was told that the closest pharmacy that was open was about 45-60mins drive away.
I’ve lived in Southampton for 18 years now, and years ago I knew there were multiple pharmacies in Southampton that were open until late at night – and one that I think was open 24 hours a day. I was intrigued to see how much this had changed, and managed to find a NHS dataset giving opening hours for all NHS community pharmacies. These data are available back to 2022 – so only ~3 years ago – but I thought I’d have a look.
The results shocked me: between 2022 and 2025, the number of pharmacies open past 9pm on a week day has decreased by approximately 95%! And there are now large areas of the country where there are no pharmacies open past 9pm on any week day.
I mentioned this to some friends, one of them put me in touch with a journalist, I sent them the data and was interviewed by them and the result is this article. In case you can’t access it, I’ll quote a couple of the key paragraphs here:
The number of late-night pharmacies in England has fallen more than 90 per cent in three years, according to an analysis of NHS data, raising fresh concerns about patient access to out-of-hours care.
…
The analysis of official NHS records was carried out by geospatial software engineer Robin Wilson and verified by the FT. Wilson, from Southampton, crunched the numbers after his wife had to make a two-hour round trip to collect his prescription for back pain that left him “immobilised”.
I’ll aim to write another post about how I did the analysis sometime, but it was mosly carried out using Python and pandas, along with some maps via GeoPandas and Folium. The charts and maps in the article were produced by the FT in their house style.
I don’t seem to have time or energy for long posts these days, but here’s another quick post which might save you some time and frustration.
Recently, I’ve been trying to import OpenStreetMap data into a PostGIS database to use with pgRouting. I wanted to import data for the whole of England – which has quite a lot of roads!
I initially tried following standard guides online, to do roughly the following:
This takes the england_latest.osm file, uses a config for cars (so it doesn’t try to route down paths, but only routes that are accessible to cars), specifies how to connect to the database, what schema to use and what prefix to use.
I tried running this and it ran for hours and hours and eventually crashed with loads of errors of the form:
While processing FROM 1800000th to: 1820000th way
count1820000 While processing FROM 1800000th to: 1820000th way
[********************| ] (40%) Total processed: 1840000
ERROR: relation "__ways8380" does not exist
I eventually worked out that the way to solve this is to add a --chunk 10000000 parameter to the command line call. This is a big increase on the default chunk size, and has two benefits:
It stops it crashing – which is always good!
It massively speeds up the import, taking it from running for many hours (and then failing) to finishing successfully in about 45mins
I’m not entirely sure how the larger chunk size stops the crash, but the speedup seems to come because osm2pgrouting uses the Postgres COPY command (which is very efficient), and with a larger chunk size it runs the COPY command a few times with large chunks of data rather than loads of times with small chunks of data.
Warning: You will need a computer with a lot of RAM to run this successfully with a large chunk size. I used a temporary cloud VM with a large amount of RAM which only cost me about £5.
A Discord server I use has a channel called #til, standing for Today I Learned. It’s a place to post interesting or surprising things you recently learned.
I took my posts to that channel from the last couple of years, tidied them up and have listed them below. Hopefully you’ll find something interesting there:
TIL that elements with even atomic numbers are more abundant than elements with odd atomic numbers, because of the way elements are formed through fusion. [Source]
TIL that the BCG vaccine (for TB, you may have had it as a child/teenager) is also an effective chemotherapy treatment for bladder cancer, apparently by causing a local immune reaction against the tumor. [Source]
TIL how guns are traced by serial numbers in the US, with no computers allowed. [Source]
TIL a lot about the extremely complex engineering behind the Manhattan Project. [Source]
TIL more details about how various types of display screens work. [Source]
TIL that by freezing (literally, lowering the temperature significantly) a RAM chip, you can keep the values there for a while after removing power, allowing attackers to extract chips and read them [Source]
TIL that when replacing some ball-and-socket joints, surgeons will sometimes reverse the joint when the natural socket is badly damaged. [Source]
TIL that the British Library was only created in 1973 as a combination of several earlier libraries, including the British Museum Library. [Source]
TIL that a PDF of the first issue of Linux Format magazine (from 2000) is available online, featuring distributions like Mandrake and Corel Linux. [Source]
TIL how much the UK National Lottery was played in the 1990s, with around two-thirds of adults buying tickets weekly, despite extremely poor odds. [Source]
TIL about the Volkswagen sausage — a genuine VW product with an official part number. [Source]
TIL that UK police operate at least one fixed-wing aircraft as well as helicopters (and when I learned this it was circling over my house). [Source]
TIL that in 1841, the population of Ireland was 8.2 million, more than three times that of Scotland, and over half that of England. Then the potato blight came. There are still fewer people living on the island of Ireland than there were in 1841. I knew the Irish potato famine was bad, but I hadn’t realised the population had never grown back to the levels before it. [Source]
TIL that the processor name Pentium comes from pent meaning five — effectively the successor to the 486 (i.e. 586).
TIL that pyrophones are musical instruments that produce sound via explosions or rapid heating, described as “internal combustion instruments.” [Source]
TIL that Plymouth has roughly double the population of Exeter – for some reason I thought Exeter was larger. [Source][Source]
TIL about the enormous complexity involved in building and operating semiconductor fabrication plants. [Source]
TIL that datacentres consumed 18% of Ireland’s electricity in 2021–22, and likely more since. [Source]
TIL that there is a place in England called New Invention, with debate over what the invention actually was. [Source]
TIL about the surprisingly varied cow silhouettes used on European road signs. [Source]
TIL about the idea that “the rain follows the plough,” a mistake of correlation for causation suggesting that starting to farm desert/dry lands will bring rain [Source]
TIL that a radio station for biscuit-factory employees became Britain’s first independent radio station. [Source]
TIL about unusual and humorous units of measurement. [Source][Source]
TIL that apparently I had completely the wrong idea about belly dancing. I assumed you danced on your belly, but apparently the thing I was picturing was breakdancing. [Source]
I really haven’t got much time or energy at the moment (I spent most of the Christmas break with an extremely painful back, which was exhausting and frustrating), but I wanted to post a very brief list of books I read this year. I read a total of 44 books this year, which includes re-reads and audiobooks. A lot of them aren’t included here as they’ve been included in other lists I’ve posted, or are childrens books I’ve been re-reading.
The books listed below have a significant tech/nerd/infrastructure focus, but cover a fairly broad set of fields even so. I hope you find something interesting to add to your ‘to read’ list!
Killing Thatcher – About the attempted assassination of Thatcher by the IRA. Fascinating in general, covers a lot of Irish/British history, police approaches, IRA structures and so on. I learned a lot, was shocked by a lot, and thoroughly enjoyed reading it.
A Brush with Steam: David Shepherd’s Railway Story – Very good, lots of stuff about how the early steam preservation movement got going, plus crazy tales of African railways in the 60s. Remarkably funny in places, with absurd BR bureaucracy and things falling off the back of lorries.
Concorde – One of the best Concorde books I’ve read, with a load of stuff that was new to me.
The Boy Who Played with Fusion – I read The Radioactive Boy Scout last year, and found it really depressing. This is a far happier book, and still interesting.
Fuelling the Wars: PLUTO and the Secret Pipeline Network 1936–2015 – Very good; fascinating the way the oil pipeline network in the UK developed over the years, and the amount of infrastructure involved. Something I knew barely anything about before, but I’m now pointing out ‘pipeline posts’ to my wife when driving down country roads!
Petroleum Refining in Nontechnical Language – Bits of it were a bit above me (I only did chemistry to GCSE level), but it gave me a far better idea of what goes on at the oil refinery near us (Fawley, on the shore of Southampton Water).
A Classless Society: Britain in the 1990s by Alwyn W. Turner – a fascinating tour through the 1990s in Britain, covering everything from politics and law to popular culture. As someone who lived through the decade but didn’t really pay attention to the wider world (I was still a young child), it was fascinating.
I’ve got into a bit of a habit of writing occasional posts with links to interesting things I’ve found (probably because it’s a relatively easy blog post to write). This is another of those posts – this time, written in June 2025. So, let’s get on with some links:
Why COUNT(*) can be slow in Postgres: a good delve into how Postgres works ‘under the hood’ and why that means that counting rows can sometimes be quite time-consuming
f2: handy command-line tool for bulk-renaming files, with the default mode being a dry-run
Leaflet v2.0 alpha: an alpha version of a new major version of Leaflet, the web mapping library. I actually tend to use MapLibre these days (it seems faster for MVTs, though I haven’t tested that properly), but I prefer the Leaflet API and tend to use it for simpler applications. The new version seems to tidy up a lot of stuff, which is good.
cqlalchemy: this is a handy library (named after SQLAlchemy and almost impossible to pronounce in a way that makes clear it is different) for writing Common Query Language queries, as used with many STAC catalogs. It’s a right pain to write these queries by hand, and they often have to be structured weirdly in JSON, but this library will do it all for you.
stac-fastapi-geoparquet: this is a backend for the stac-fastapi tool (a STAC server written in FastAPI) that lets you store the STAC catalog in GeoParquet rather than in the standard options of a Postgres database (via pgstac) or ElasticSearch. Storing STAC information in GeoParquet files is something I’ve been keeping an eye on for a while, and there are some interesting talks on it – like this one.
stac-auth-proxy: One final STAC-related link, this time an authentication proxy to run a private, secured STAC server. This is something I implemented a proof of concept of myself with a previous client, and it’s nice to see there’s something ‘off the shelf’ for it now.
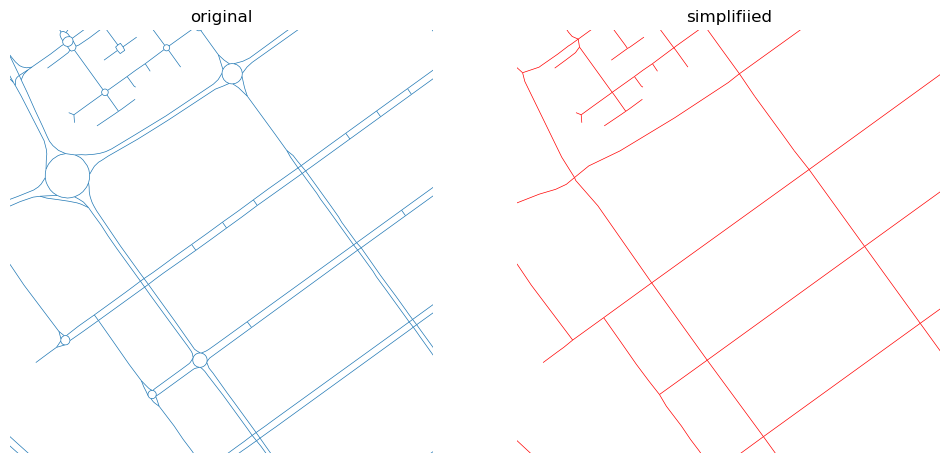
Simplification of street networks: A nice description of a Python tool to simplify street networks, removing things like sliproads, roundabouts and so on, and just leaving the correct topology there. It’s quite a nice tool, but also a nice approach to solving the problem.
Promptfoo: This looks like a good tool for evaluating AI model responses – easily configurable, open-source etc. There’s a good description of the tool and links to other resources on Simon’s blog. Another interesting post on evals for AI model responses is here.
Adding notes to exceptions in Python: a brief post explaining a new feature in Python 3.11 which allows you to add handy notes to exceptions – I could see this being useful for some more complex errors in some of my libraries
How to get auto-complete to automatically appear in pgAdmin: I’m not a massive fan of pgAdmin, but I’ve tried a range of Postgres GUIs and haven’t really found one I like more (yet…). This little change to the settings in pgAdmin will make it pop up the autocomplete dropdown when writing SQL queries just while you’re typing, rather than waiting for you to press a key combination – making everything a little bit smoother.
Design for 3D printing: I’ve been getting quite into 3D printing recently (I’m hoping to write a post on it soon), and this is a great, very detailed, article on how to design items ready for 3D printing. I learnt a lot!
llm can run tools now: Simon’s llm command-line tool and Python library can now use the ‘tool usage’ pattern with local tools defined very easily as Python functions. Seems very powerful, and a lot simpler than some other approaches.
I recently gave a careers talk to students at Solent University, and through that I got to know a MSc student there who had previous GIS experience and was now doing a Data Analytics and AI MSc course. Her GIS experience was mostly in the ESRI stack (ArcGIS and related tools) and she was keen to learn other tools and how to combine her new Python and data knowledge with her previous GIS knowledge. I wrote her a long email with links to loads of resources and, with her permission, I’m publishing it here as it may be useful to others. The general focus is on the tools I use, which are mostly Python-focused, but also on becoming familiar with a range of tools rather than using tools from just one ecosystem (like ESRI). I hope it is useful to you.
Tools to investigate:
GDAL
GDAL is a library that consists of two parts GDAL and OGR. It provides ways to read and write geospatial data formats like shapefile, geopackage, GeoJSON, GeoTIFF etc – both raster (GDAL) and vector (OGR). It has a load of command-line tools like gdal_translate, ogr2ogr, gdalwarp and so on. These are extremely useful for converting between formats, importing data to databases, doing basic processing etc. It will be very useful for you to become familiar with the GDAL command-line tools. It comes with a Python interface which is a bit of a pain to use, and there are nicer libraries that are easier for using GDAL functionality from Python. A good tutorial for the command-line tools is at https://courses.spatialthoughts.com/gdal-tools.html
Command line tools in general
Getting familiar with running things from the command-line (Command Prompt on Windows) is very useful. On Windows I suggest installing ‘Windows Terminal’ (https://apps.microsoft.com/detail/9n0dx20hk701?hl=en-GB&gl=GB) and using that – but make sure you select standard command prompt not Powershell when you open a terminal using it.
GeoPandas – like pandas but including geometry columns for geospatial information. Try the geopandas explore() method, which will do an automatic webmap of a GeoPandas GeoDataFrame (like you did manually with Folium, but automatically)
rasterio – a nice wrapper around GDAL functionality that lets you easily load/manipulate/save raster geospatial data
fiona – a similar wrapper for vector data in GDAL/OGR
shapely – a library for representing vector geometries in Python – used by fiona, GeoPandas etc
rasterstats – a library for doing ‘zonal statistics’ – ie. getting raster values within a polygon, at a point etc
Conference talks
These can be a really good way to get a brief intro to a topic, to know where to delve in deeper later. I often put them on and half-listen while I’m doing something else, and then switch to focusing on them fully if they get particularly interesting. There are loads of links here, don’t feel like you have to look at them all!
FOSS4G conference YouTube videos:https://www.youtube.com/@FOSS4G/videos – they have a load of ones from 2022 at the top for some reason, but if you scroll down a long way you can find 2023 and 2024 stuff. Actually, better is to use this playlist of talks from the 2023 global conference: https://www.youtube.com/playlist?list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ
Here’s a few talks that might be particularly interesting/relevant to you, in no particular order
Suggestions for learning projects/tasks (These are quite closely related to the MSc project that this student might be doing, but are probably useful for people generally)
I know when you’re starting off it is hard to work out what sort of things to do to develop your skills. One thing that is really useful is to become a bit of a ‘tool polyglot’, so you can do the same task in various tools depending on what makes sense in the circumstances.
I’ve listed a couple of tasks below. I’d suggest trying to complete them in a few ways:
Using QGIS and clicking around in the GUI
Using Python libraries like geopandas, rasterio and so on
Using PostGIS
(Possibly – not essential) Using the QGIS command-line, or model builder or similar
Download OS data on buildings from this page – https://automaticknowledge.org/gb/ – you can download it for a specific local authority area
Find all buildings at risk of flooding, and provide a count of buildings at risk and a map of buildings at risk (static map or web map)
Extension task: also provide a total ground area of buildings at risk
Task 2 – Elevation data
(Don’t do this with PostGIS as its raster functionality isn’t great, but you could probably do all of this with GDAL command-line tools if you wanted)
Mosaic the tiles together into one large image file
Do some basic processing on the DEM data. For example, try:
a) Subtracting the minimum value, so the lowest elevation comes out as a value of zero
b) Running a smoothing algorithm across the DEM to remove noise
I did a post a while back which was just a lot of links to things I found interesting, mostly in the geospatial/data/programming sphere. Since then I’ve collected a lot more links – so here are some of them. The theme, such as there is, seems to be ‘this would have really helped me about X contracts ago, if it had existed then/I had known about it then’. Make of that what you will…
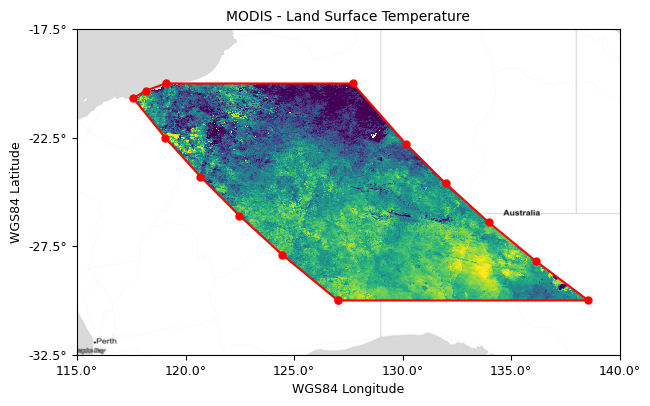
The stac-tools raster footprint utility – a useful new-ish tool that generates nice, accurate but simple outlines (‘footprints’) for the area covered by a raster file (as shown above) all ready to put into a STAC catalog
Is Antarctica Greening? – a brief article looking at some of the technicalities of using NDVI time series to monitor greening in Antarctica (reminds me of some of the issues I had using time series in my PhD)
VTracer – an interactive web interface to an open-source tool to convert raster images to vector SVGs (not geospatial images, just images in general). Gives great immediate feedback on parameter changes
tilegroxy – a proxy that can sit between end users of web map raster/vector tiles and the sources, managing things like caching, authentication etc. Seriously considering using this with my current client.
grid-banger – a Python package for converting between Ordnance Survey grid co-ordinates and latitude/longitude. Unlike many converters, it works with both fully numerical grid references, and those that start with letters (like TQ213455)
GeoDeep – a new and simple (but seemingly quite powerful) tool for doing basic deep learning on geospatial rasters. Can do things like extract cars, trees, buildings – and even extract road polygons (something which would have been useful a couple of clients ago…)
LosslessCut – not geospatial or data related, but very useful: I’ve recently been digitising some old VHS tapes, and this makes it very easy to mark chunks of video files and then export each chunk to a separate file – all while keeping the quality high
labellines – a neat little Python package for labelling lines on a graph by putting the label inside the line, rather than relying on a separate legend (see image below)
act – lets you run Github Actions locally, to save doing a million commits to see how your CI/deployment/etc runs. This would have saved me a lot of time about four contracts ago.
cuttle – this one isn’t even tech related, it’s the rules for a fairly fun card game that I’ve been playing with my wife recently. Sometime I’ll do a blog post containing my player cheatsheet that I put together.
It’s cool to care – a blog post from Alex Chan where they explain something that is very important to me: that it is cool to be enthusiastic/interested/excited by something, even if other people aren’t.
FILTER in Postgres – simple explanation of a nice bit of SQL syntax in Postgres that allows you to write things like SELECT COUNT(*) FILTER (WHERE b > 11)
QMapCompare plugin for QGIS – a useful plugin that lets you compare two views of a map, either side-by-side, with a swipe or with a focus area following the map
BGNix – a 100% free way to remove backgrounds from images (again, not geospatial in this case – just things like photos or clipart). It uses an AI model that runs entirely on your local device, and so doesn’t send your images anywhere making it high-privacy too!
Spy for changes with sys.monitoring – nice example of how to use the new sys.monitoring functionality (a newer, better version of sys.settrace) in Python to help with debugging
QGIS Deepness – a plugin for easily running deep learning models in QGIS, including a ‘model zoo’ of models that can be set up very quickly
lonboard – I mentioned lonboard in my last list of links – it’s a Python library for creating interactive maps – but hugely faster than most alternatives. Here’s a new version with animation added, allowing some pretty cool animated maps to be made.
geopandas – another new release, this time for geopandas with some nice new functionality
As always, this post is very delayed – apologies. In fact, I was encouraged to write this by a friend who I see at PyData Southampton (Hi, if you’re reading this!). I mentioned my talk in passing to her, and she asked if I’d blogged about it yet. I admitted that I hadn’t, and promised I would by the next PyData Southampton. Well, I totally failed at that – but there is another PyData Southampton meetup on Tuesday, so I’m going to get it done in time for that.
The FOSS4G UK South West conference 2024 took place in Bristol on 12th November. I gave a talk there entitled Using cloud-native geospatial technologies to build a web app for analysing and reducing flood risk, talking about some of the work I’ve done with the company I’m currently working with: Rebalance Earth.
The talk covers the development of a web app for looking at assets (businesses, buildings, substations etc) that are at risk from flooding in the UK, and comparing various flood scenarios to understand how risk could be reduced by Natural Flood Management strategies such as river restoration. After introducing Rebalance Earth and the web app itself, I talk about the technologies behind it and the ‘cloud native’ manner in which it was designed. I specifically cover generating Mapbox Vector Tiles on-the-fly from a PostGIS database, and generating raster tiles on-the-fly from COG files stored in cloud storage.
Full slides are available here. There is also a video recording of the talk available, but it’s a bit hard to watch as you can’t see the slides on the video.
Once you’ve had a look at my talk, don’t forget to check out the other talks that were given at the conference, they were great!