Summary: It might be because there is an exception raised when importing your function_app.py – for example, caused by one of your import statements raising an exception, or a parsing error caused by a syntax error.
I was deploying a FastAPI app to Azure Functions recently. Azure Functions is the equivalent of AWS Lambda – it provides a way to run serverless functions.
Since I’d last used Azure Functions, Microsoft have introduced the Azure Functions Python V2 programming model which makes it easier and cleaner to do a number of common tasks, such as hooking up a FastAPI app to run on Functions.
However, it also led to an error that I hadn’t seen before, and that I couldn’t find documented very well online.
Specifically, I was getting an error at the end of my function deployment saying No HTTP triggers found. I was confused by this because I had followed the documented pattern for setting up a FastAPI app. For reference, my function_app.py file looked a bit like this:
import azure.functions as func
from complex_fastapi_app import app
app = func.AsgiFunctionApp(app=app,
http_auth_level=func.AuthLevel.ANONYMOUS)
This was exactly as documented. But I kept getting this error – why?
I replaced the import of my complex_fastapi_app with a basic FastAPI app defined in function_app.py, this time copied directly from the documentation:
Everything worked fine now and I didn’t get the error.
After a lot of debugging, it turns out that if there is an exception raised when importing your function_app.py file then Functions won’t be able to establish what HTTP triggers you have, and will give this error.
In this case, I was getting an exception raised when I imported my complex_fastapi_app, and that stopped the whole file being processed. Unfortunately I couldn’t find anywhere that this error was actually being reported to me – I must admit that I find Azure logging/error reporting systems very opaque. I assume it would have been reported somewhere – if anyone reading this can point me to the right place then that’d be great!
I’m sure there are many other reasons that this error can occur, but this was one that I hadn’t found documented online – so hopefully this can be useful to someone.
Summary: If appending to a PostGIS table with GDAL/OGR is taking a long time, try setting the PG_USE_COPY config option to YES (eg. adding --config PG_USE_COPY YES to your command line). This should speed it up, but beware that if there are concurrent writes to your table at the same time as OGR is accessing it then there could be issues with unique identifiers.
As with many of my blog posts, I’m writing this in the hope that it will appear in searches when someone else has the same problem that I ran into recently. In the past I’ve found myself Googling problems that I’ve had before and finding a link to my blog with an explanation in a post that I didn’t even remember writing.
Anyway, the problem I’m talking about today is one I ran into when working with a client a few weeks ago.
I was using the ogr2ogr command-line tool (part of the GDAL software suite) to import data from a local Geopackage file into a PostGIS database (ie. a PostgreSQL database with the PostGIS extension).
I had multiple files of data that I wanted to put into one Postgres table. Specifically, I was using the lovely data collated by Alasdair Rae on the resources page of his website. Even more specifically, I was using some of the Local Authority GIS data to get buildings data for various areas of the UK. I downloaded multiple GeoPackage files (for example, for Southampton City Council, Hampshire County Council and Portsmouth City Council) and wanted to import them all to a buildings table.
I originally tested this with a Postgres server running on my local machine, and ran the following ogr2ogr commands:
Here I’m using the -f switch and the arguments following it to tell ogr2ogr to export to PostgreSQL and how to connect to the server, giving it the input file of buildings1.gpkg and using the -nln parameter to tell it what layer name (ie. table name) to use as the output. In the second command I do exactly the same with buildings2.gpkg but also add -append and -update to tell it to append to the existing table rather than overwriting it.
This all worked fine. Great!
A few days later I tried the same thing with a Postgres server running on Azure (using Azure Database for PostgreSQL). The first command ran fine, but the second command seemed to hang.
I was expecting that it would be a bit slower when connecting to a remote database, but I left it running for 10 minutes and it still hadn’t finished. I then tried importing the second file to a new table and it completed quickly – therefore suggesting it was some sort of problem with appending the data.
I worked round this for the time being (using the ogrmerge.py script to merge my buildings1.gpkg and buildings2.gpkg into one file and then importing that file), but resolved to get to the bottom of it when I had time.
Recently, I had that time, and posted on the GDAL mailing list about this. The maintainer of GDAL got back to me to tell me about something I’d missed in the documentation. This was that when importing to a brand new table, the Postgres COPY mode is used, but when appending to an existing table individual INSERT statements are used instead, which can be a lot slower.
Let’s look into this in a bit more detail. The PostgreSQL COPY command is a fast way of importing data into Postgres which involves copying a whole file of data into Postgres in one go, rather than dealing with each row of data individually. This can be significantly faster than iterating through each row of the data and running a separate INSERT statement for each row.
So, ogr2ogr hadn’t hung, it was just running extremely slowly, as inserting my buildings layer involved running an INSERT statement separately for each row, and there were hundreds of thousands of rows. Because the server was hosted remotely on Azure, this involved sending the INSERT command from my computer to the server, waiting for the server to process it, and then the server sending back a result to my computer – a full round-trip for each row of the table.
So, I was told, the simple way to speed this up was to use a configuration setting to turn COPY mode on when appending to tables. This can be done by adding --config PG_USE_COPY YES to the ogr2ogr command. This did the job, and the append commands now completed nice and quickly. If you’re using GDAL/OGR from within a programming language, then have a look at the docs for the GDAL bindings for your language – there should be a way to set GDAL configuration options in your code.
The only final part of this was to understand why the COPY method isn’t used all the time, as it’s so much quicker. Even explained that this is because of potential issues with other connections to the database updating the table at the same time as GDAL is accessing it. It is a fairly safe assumption that if you’re creating a brand new table then no-one else will be accessing it yet, but you can’t assume the same for an existing table. The COPY mode can’t deal with making sure unique identifiers are unique when other connections may be accessing the data. whereas individual INSERT statements can cope with this. Therefore it’s safer to default to INSERT statements when there is any risk of data corruption.
As a nice follow-up for this, and on the maintainer’s advice, I submitted a PR to the GDAL docs, which adds a new section explaining this and giving guidance on setting the config option. I’ve copied that section below:
When data is appended to an existing table (for example, using the -append option in ogr2ogr) the driver will, by default, emit an INSERT statement for each row of data to be added. This may be significantly slower than the COPY-based approach taken when creating a new table, but ensures consistency of unique identifiers if multiple connections are accessing the table simultaneously.
If only one connection is accessing the table when data is appended, the COPY-based approach can be chosen by setting the config option PG_USE_COPY to YES, which may significantly speed up the operation.
I ran into a situation recently where I needed to create a Windows 10 bootable USB stick. I could easily download a Windows 10 ISO file, but I knew that it needed some ‘special magic’ to write it to a USB stick that would boot properly.
I tried various solutions (including windiskwriter) but none of them worked – until I tried Ventoy.
I got rather confused when reading the Ventoy webpage, so I wanted to write a quick blog post to show how to use it for this specific use case. The technology I had available to me was one M1 MacBook Pro running macOS and one x64 desktop machine with no OS (on which I wanted to install Windows) – and so these instructions will be based around this situation.
The way that Ventoy works is that you write the Ventoy image to a USB stick and it creates multiple partitions: some boot partitions, plus a big empty partition using up most of the space on the USB stick. You then copy your boot ISO files (for Windows, or Linux or whatever) onto that partition. When you boot from the USB stick Ventoy will provide a menu to allow you to pick an ISO, and then it will boot that ISO as if it had been burned to the USB stick itself. The easiest (and most reliable) way to write the Ventoy image to a USB stick is to use a bootable Ventoy image to do it – a double-USB-stick approach.
Burn that to a USB stick (it can be a small one) using a standard USB stick burning program like balenaEtcher
Boot from that USB stick on my x64 machine.
Insert another USB stick (ideally a fairly large one) into that machine (while keeping the first one inserted) and follow the on-screen instructions to burn Ventoy to that USB stick.
Shutdown that computer
Insert that USB stick into my Mac, and copy the Windows 10 ISO file onto the large empty partition.
Boot from that USB stick on the x64 computer. It will show an interface to allow you to choose an ISO to boot – there will be only one, so just press Enter. A few minutes later the Windows 10 installer will be ready to use.
Of course you can now keep this Ventoy USB stick around, and add other ISO files to it as needed.
I use GeoPandas for a lot of my vector GIS data manipulation in Python.
I had a situation the other day where I ended up with duplicates of some geometries in my GeoDataFrame, and I wanted to remove them. The simple way to do this is to use the underlying pandas method drop_duplicates on the geometry column, like:
gdf.drop_duplicates('geometry')
However, even after running this I still had some duplicate geometries present. I couldn’t quite believe this, so checked multiple times and then started examining the geometries themselves.
What I found was that my duplicates were technically different geometries, but they looked the same when viewing them on a map. That’s because my geometries were LineStrings and I had two copies of the geometry: one with co-ordinates listed in the order left-to-right, and one in the order right-to-left.
This is illustrated in the image below: both lines look the same, but one line has the individual vertex co-ordinates in order from left-to-right and one has the same co-ordinates in order from right-to-left.
These two geometries will show as the same when using the geometry.equals() method, but won’t be picked up by drop_duplicates. That’s because drop_duplicates just serialises the geometry to Well-Known Binary and compares those to check for equality.
I started implementing various complex (and computationally-intensive) ways to deal with this, and then posted an issue on the GeoPandas Github page. Someone there gave me a simple solution which I want to share with you.
All you need to do is run gdf.normalize() first. So, the full code would be:
gdf.normalize()
gdf.drop_duplicates('geometry')
The normalize() method puts the vertices into a standard order so that they can be compared easily. This works for vertex order in lines and polygons, and ring orders in complex polygons.
Summary: The QGIS Reloader plugin will give you a new QGIS command to reload a layer, very useful when you’re updating a layer in another program and want to refresh QGIS’s view of it.
I use QGIS for almost all of my interactive GIS needs. Often I’ll be writing some code in Python that creates some sort of GIS layer (often a GeoPackage) and then I’ll use QGIS to interactively explore that layer.
In this situation, I’ll frequently create new versions of the GIS layer. Usually I’ve dealt with this by just creating XXX_v1.gpkg, XXX_v2.gpkg and so on, and dragging them into QGIS. However, if you have some complex symbology set up on the layer in QGIS you have the additional step of copying/pasting the layer styling from the old layer to the new layer. That’s a bit of a pain, but at least it’s possible.
Recently I’ve been using the QGIS Attribute Forms functionality to display an image when clicking on a feature in a layer, and those settings can’t be easily copied between layers. If I drag in a new version of the layer then I’ll have to click through and set up all of the form settings again.
What I wanted was a way to reload the contents of a layer from the file on disk – so I could just save to the same filename each time and reload the layer in QGIS. A bit of research showed me that duplicating a layer did this (right-click the layer and click Duplicate Layer) – but that leaves you with multiple layers, and an annoying ‘copy’ appended to the name.
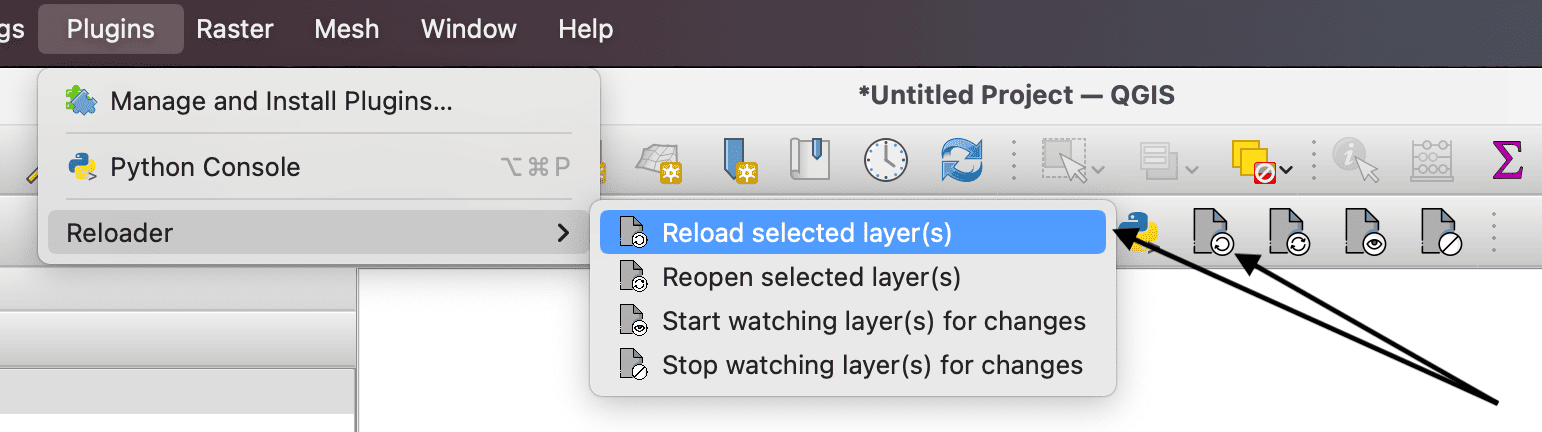
Today I found a plugin that does exactly what I need. It’s called Reloader and is available from the QGIS Plugins Repository – just search for its name. It adds some new menu entries to reload the selected layers, reopen the layers (which updates the extent too), and even start/stop watching layers for changes (with a filesystem watcher that will update the layer whenever the underlying file changes). Just what I needed!
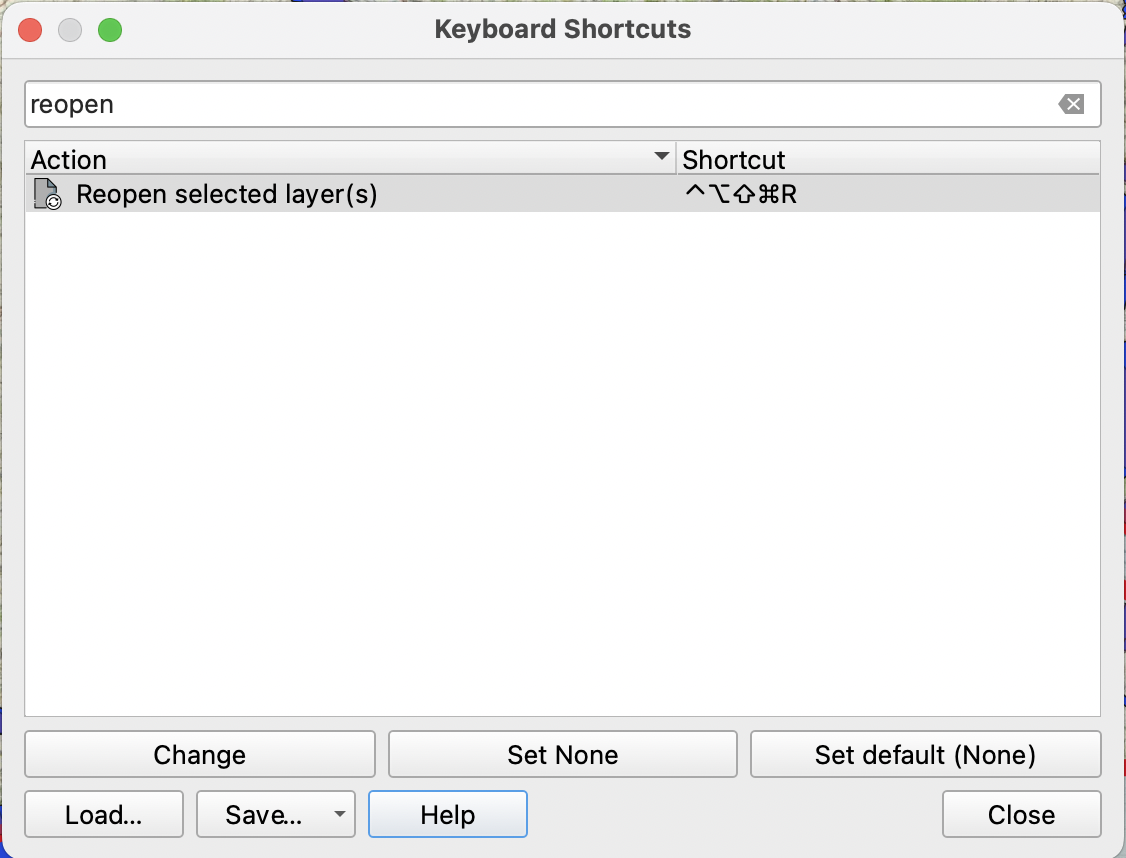
The only minor issue I have is that the menu entries come under the top-level Plugins menu, rather than in the right-click menu for an additional layer. I assume that QGIS doesn’t let plugins modify the layer context menu. However, to save going to the Plugins menu each time you can set up a keyboard shortcut for these functions. Go to Settings->Keyboard Shortcuts and search for Reload or Reopen and click the Change button to set a keyboard shortcut.
In the image above I’ve set a keyboard shortcut that looks very complex to press, but is actually easy when using my Goku configuration to get Caps Lock working as a modifier key.
Note: This blog post has been updated with a new command for creating an osx-64 environment, after I was contacted by someone from Anaconda telling me a newer, easier way to do this
I came across some conda packages that didn’t work properly on my M1 Mac (Apple Silicon – ARM processor) the other day. They installed fine, but gave segmentation faults when run. So, I wanted to run the x64 (Intel) versions of these packages instead.
I haven’t actually needed to do this since I got a M1 Mac (a testament to the quality and range of ARM conda packages available these days through conda-forge), so I wasn’t sure how to do it.
A bit of Googling and experimenting led to this nice simple set of instructions. The upshot of this is you don’t need to install another version of Anaconda/miniconda/etc – you can just create a x64 environment in your existing conda install.
In the past you used to have to prepend a CONDA_SUBDIR=osx-64 chunk to set an environment variable, but since conda 23.10.0 (released on 30th October 2023) you can use the --platform parameter instead. This tells conda to use the osx-64 packages from the package server, rather than the default osx-arm64 (M1 Mac) subdirectory. This is what gets you the x64 packages. Documentation for this option is available here, along with a list of possible platform names you can use.
When this command finishes, you will have a new x64 conda environment. You can then activate it with
conda activate environment_name
That’s it! You now have a x64 environment which you can install packages in using standard conda install commands.
Note:
The previous set of instructions here had two extra steps to deal with the CONDA_SUBDIR environment variable. I’ve included these below for anyone using an old version of conda, but these won’t be needed if you’re using the --platform parameter:
Now we need to tell conda to always use this CONDA_SUBDIR setting when using this environment, otherwise any future installs in this environment will use the default CONDA_SUBDIR and things will get very confused. We can do this by setting a conda environment config setting to tell conda to set a specific environment variable when you activate the environment. Do this by running:
conda env config vars set CONDA_SUBDIR=osx-64
The output of that command will warn you to deactivate and reactivate the environment, so do this
Just a quick one today to document the solution to a problem I ran into earlier today.
I was using Microsoft Planetary Computer to access some Landsat satellite data, and I wanted to run it through the Segment Anything model from Meta, to segment out agricultural fields from the image. I tried to do this using the segment-geospatial Python package.
Unfortunately I got an error that libgl1.so could not be found. Luckily this is documented on the segment-geospatial installation page and you just need to run:
apt update; apt install -y libgl1
But, there’s a problem: Microsoft Planetary Computer does not allow apt access from their container images. I tried every way I could think of to install this, and did a lot of googling, but couldn’t find anything.
Eventually I found the answer in this issue which somehow didn’t appear in my earlier Google searches. It seems that the libgl1 library is a dependency of OpenCV, which segment-geospatial uses interally, and you can get around this dependency by installing the opencv-python-headless package. And it was just that simple – running
pip install opencv-python-headless
completely solved the problem and let me get going running segment-geospatial.
I hope this post helps someone else with the same problem as me – and hopefully turns up better in relevant Google searches.
I’m giving two talks in the next two weeks, and wanted to publicise them here in case anyone local-ish wants to come.
Oxford Cafe Scientifique
I’ve spoken at various Cafe Scientifique meet-ups before, and now it’s the turn of the Oxford one. I’ll be giving my talk about the whole range of satellite imaging – details below. This particular cafe sci focuses has a particularly long Q&A and discussion section, so I’m looking forward to getting some real back-and-forth with the audience.
Full details here, and title and description below:
Monitoring the environment from space
Hundreds of satellites orbit the Earth every day, collecting data that is used for monitoring almost all aspects of the environment. This talk will introduce to you the world of satellite imaging, take you beyond the ‘pretty pictures’ to the scientific data behind them, and show you how the data can be applied to monitor plant growth, air pollution and more.
PyData Southampton
Before the pandemic I was part of a group trying to set up a PyData Southampton group – but unfortunately it got derailed by lockdown. Luckily, we’ve managed to resurrect it, and the first meeting will be on Tues 17th October at the Carnival offices near IKEA in Southampton. If you enjoy Python and data stuff then come along!
Full details here and title and description below:
An Introduction to geospatial data & processing
In this talk, Robin will introduce geospatial data and how to process it using Python. He’ll explain what geospatial data is, and what makes it different from normal data. He’ll cover the types of geospatial data, issues relating to co-ordinate systems, and where to get geospatial data, before diving into a couple of case studies of geospatial data processing with Python using libraries including GeoPandas, rasterio, shapely, rasterstats, folium and more.
In the spirit of my Previously Unpublicised Code series, today I’m going to share Pandas-FSDR. This is a simple library with one function which finds significant differences between two columns in a pandas DataFrame.
For example, imagine you had the following data frame:
Subject
UK
World
Biology
50
40
Geography
75
80
Computing
100
50
Maths
1500
1600
You may be interested in the differences between the values for the UK and the World (these could be test scores or something similar). Pandas-FSDR will tell you – by running one function you can get output like this:
Maths is significantly smaller for UK (1500 for UK compared to 1600 for World)
Computing is significantly larger for UK (100 for UK compared to 50 for World)
Differences are calculated in absolute and relative terms, and all thresholds can be altered by changing parameters to the function. The function will even output pre-formatted Markdown text for display in an IPython notebook, inclusion in a dashboard or similar. The output above was created by running this code:
result = FSDR(df, 'UK', 'World', rel_thresh=30, abs_thresh=75)
This is a pretty simple function, but I thought it might be worth sharing. I originally wrote it for some contract data science work I did years ago, where I was sharing the output of Jupyter Notebooks with clients directly, and wanted something that would ‘write the text’ of the comparisons for me, so it could be automatically updated when I had new data. If you don’t want it to write anything then it’ll just output a list of row indices which have significant differences.
Anyway, it’s nothing special but someone may find it useful.
GeoParquet is a cool new-ish format for geospatial data. I’ve tried to use it a couple of times, but always run into issues with my GDAL/OGR install not supporting it. Each time this has led to me giving up, as I couldn’t be bothered to install GDAL from somewhere else.
Today, I found the solution. I usually use GDAL from conda-forge, and it turns out you can install GeoParquet support for that GDAL by just installing an extra conda-forge package:
(feel free to replace conda with mamba if – like me – you’re using mamba for its speed improvements).
Once this is installed, GeoParquet works in everything that uses that GDAL library – in my case this included the GDAL/OGR command-line tools, plus various Python modules that link to GDAL.
This is actually documented at the end of the GDAL GeoParquet driver page, but I don’t think I’d ever scrolled to the bottom of that before.